AI Self-Learned To Play Thousands Of Games, Winning Over Human Players
Dhir Acharya - Jun 04, 2019

Though this was previously considered too complex even for algorithms, an AI agent has been developed capable of winning at online multiplayer games.
- 6 Cutting-Edge Features of Galaxy AI & Lineup of Supported Samsung Smartphones
- 4 Ways AI Could Change The Mobile Gaming Industry
- New ‘Deep Nostalgia’ AI Allow Users To Bring Old Photos To Life
Although this was previously considered too complex even for algorithms, an AI agent has been successfully developed which is capable of winning at online multiplayer games.
In particular, a group of scientists at DeepMind research company, owned by Google, managed to produce AI agents to play in Capture the Flag - a variant of Quake III Arena. In this game, two teams go against each other in random environments, they have to find and take the enemy’s flags around the map.
The team, led by Max Jaderberg, used reinforcement learning technique in parallel gameplay to build the agents.
After being trained through 450,000 games, the bots could win over professional human players.

There are three machine-learning paradigms, unsupervised, supervised, and reinforcement learning. The last one doesn’t involve definitive input-output pairs, and it doesn’t require erasure or correction of imperfect actions.
Rather than that, it balances between exploring an unknown domain and exploiting any knowledge gather about it, perfect for the conditions that are always changing among a load of agents, like the ones in an online multiplayer game.
DeepMind aimed at creating agents that self-learned with the same initial information as a human player, which meant there was no ability to communicate or share notes outside the game, no policy knowledge, while previous iterations provided the software models with the environment or other players’ state.
The company optimized the process by putting agents in a lot of games at the same time, putting together the results to get an overview of what tricks and tips each agents has obtained. Then they distributed that knowledge to the next generation.
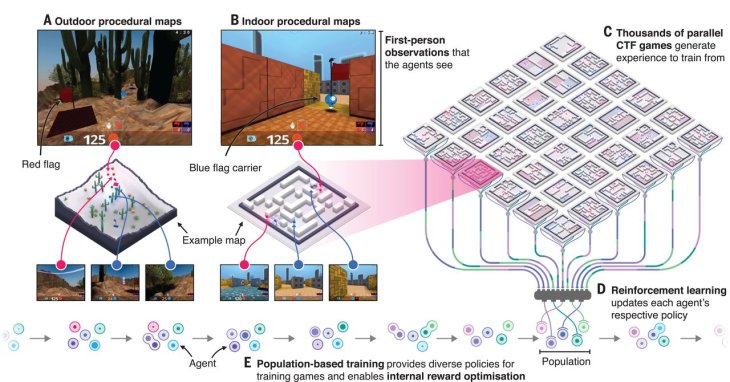
The agents, like human players, gain experience about the strategy that they can apply in a new map though they don’t know about its layout as well as topology, or the position and intent of other players. Jaderberg and his colleagues wrote:

The reinforcement learning process has two steps, including optimizing the behavior of one agent for rewards, which is then matched with the entire dataset’s hyper-parameters. They replaced underperforming agents with mutated offspring internalizing the lessons grabbed around the board, aka population-based training.
What they got were remarkable. The agents exceeded human in the games even if the system slowed their reaction times down to human’s average levels. After practicing for hours, human gamers couldn’t beat AI agents in any more than 25 percent of attempts. What’s worth noting here is that the agents learned and applied the same tactics which human players often used.
However, the key may lie in the parallel, multi-game methodology. In similar self-learning systems, AI agents learned against their own policies in a single exercise, which means they play against themselves.
And what the team is really excited about is not just applying this in gaming, but other applications in multi-agent systems involving stable learning.
Featured Stories
Features - Dec 18, 2024
6 Cutting-Edge Features of Galaxy AI & Lineup of Supported Samsung Smartphones

Features - Jan 23, 2024
5 Apps Every Creative Artist Should Know About

Features - Jan 22, 2024
Bet365 India Review - Choosing the Right Platform for Online Betting

Features - Aug 15, 2023
Online Casinos as a Business Opportunity in India

Features - Aug 03, 2023
The Impact of Social Media on Online Sports Betting

Features - Jul 10, 2023
5 Most Richest Esports Players of All Time

Features - Jun 07, 2023
Is it safe to use a debit card for online gambling?

Features - May 20, 2023
Everything You Need to Know About the Wisconsin Car Bill of Sale

Features - Apr 27, 2023
How to Take Advantage of Guarantee Cashback in Online Bets

Features - Mar 08, 2023
Comments
Sort by Newest | Popular