Google To Train Its AI To Recognize 9 Indic Languages
Aadhya Khatri - Oct 01, 2019

The system of Google could recognize nine Indic languages, including Hindi, Bengali, Malayalam, Telugu, Gujarat, Marathi, Kannada, Tamil, and Urdu
- Google Assistant Now Makes It Irresistible To Wear Face A Mask
- Here's How To Get A Makeshift Podcast From Any Text-Based Story
- How To Curb Your Roommate's Laziness: Google Assistant's 'Sticky Notes'
There are thousands of languages spoken all over the world. So far, we have had records of around 6,500, and systems from tech giants like Amazon, Apple, Facebook, and Google are getting better at recognizing them. The problem is, training these AIs requires large corpora, and we do not exactly have that for every language.
To solve this problem, Google is applying knowledge it learns from languages with lots of data to the data-scarce ones. This attempt has proven to be fruitful as the company has developed a multilingual speech parser that can transcribe several tongues. The invention was introduced at the Interspeech 2019 conference taking place in Graz, Austria.
The authors said that their system could recognize nine Indic languages, including Hindi, Bengali, Malayalam, Telugu, Gujarat, Marathi, Kannada, Tamil, and Urdu, with a high level of accuracy, all while improving dramatically the quality of ASR (short for automatic speech recognition).
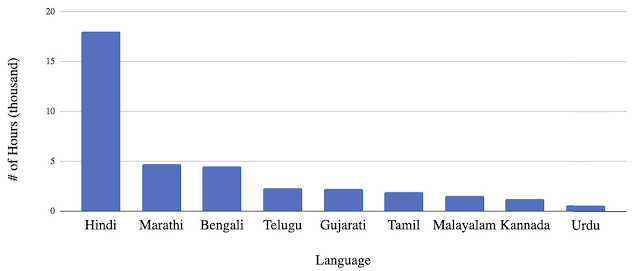
According to Anjuli Kannan and Arindrima Datta, software engineers at Google Research, the company picked India for this study because the country speaks over 30 languages and the number of native speakers is more than a million. Since the speakers of these tongues sometimes live close to each other and have shared cultural traits, many of them overlap when it comes to lexical and acoustic content.
More importantly, may Indians speak more than one language, so they may use words and phrases deriving from different tongues in one conversation.
The architecture of this system combines pronunciation, language components, and acoustic into one. Other ASRs before it can only do this without real-time speech recognition. On the other hand, the AI of Kannan, Dattan, and their colleagues makes use of a recurrent neural network transducer designed to output words one character at a time, for several languages.
To avoid bias arises from a small amount of input data set, the experts of this project tweaked the system architecture a little bit to add in language identifier input. For example, they will take the preferred language on a smartphone into consideration. This, coupled with the audio input, enable the system to learn different features of separate languages as well as to disambiguate a given one.
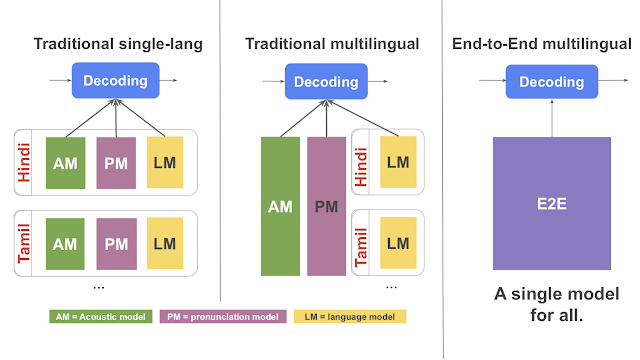
The model was then further augmented as the team allocated extra parameters for each language, which comes in the form of residual adapter modules. This will help to enhance the overall performance and fine-tune the global per-language system.
What they achieved is a system that can deal with several languages with a performance surpassing all other recognizers that work on one single language only. All of that comes with simplified serving and training all while fulfilling the requirement latency needed for tools like Google Assistant.

The researchers said that based on the results of this study, they would continue to expand the scope to other language groups to meet the need of the ever-growing number of diverse users. Google's missions are to organize global information as well as making it accessible to as many people as possible, meaning the data must be available in multiple languages.
This new system and the like will highly likely come to Google Assistant, which now has support for multiple tongues for multiturn conversations in Hindi, Korean, Norwegian, Swedish, Dutch, and Danish.
This study puts a focus on India, a nation speaking multiple languages. And it is a common phenomenon in the country for people to use a few tongues in one conversation, making it a natural case for the company to train its one single multilingual system.
Featured Stories

ICT News - Jan 18, 2024
PDF Prodigy: Expert Techniques for Editing

ICT News - Aug 03, 2023
The Psychology of Casino Game Design

ICT News - May 17, 2022
3 Reasons your privacy gets compromised online

ICT News - May 11, 2022
Apple Devices For Sale

ICT News - Apr 12, 2022
Pin-Up Review India 2022

ICT News - Mar 29, 2022
Choosing between a shared and a dedicated server for gaming

ICT News - Mar 18, 2022
How The Internet Came Into Being

ICT News - Mar 17, 2022
The Best Gaming Tech of 2022

ICT News - Feb 16, 2022
Technologies that enable the development of online casinos with live dealers

ICT News - Feb 08, 2022
Comments
Sort by Newest | Popular